* 통계에 대한 기초적 지식
1) n개의 확률변수 Xi가 서로 독립이며 Xi~N(mu, sigma^2) 일 때,
X bar ~ N(mu, sigma^2/n)
X bar에 대한 표준화 확률변수 Z = X bar - mu/ (sigma/sqrt(n)) ~ N(0,1)
이 때, sigma/sqrt(n)을 SEM, standard error of mean (표준오차)라고 한다. 표준오차는 모평균의 추정치인
표본평균 이 가지는 표준편차(standard deviation of the sample-mean's estimate of a population mean) 임.

2) n개의 확률변수 Xi가 서로 독립이며 Xi~N(mu, sigma^2)일 때, 모집단의 분산 sigma^2를 모르는 경우
표본의 분산인 s^2으로 대치해서 사용할 수 있다. 이 때, sigma가 s로 대치된 확률변수 T는 정규분포 N이
아닌 t분포를 따르는 것으로 알려져 있다. t분포는 자유도(df=n-1)에 따라 분포의 모양이 달라지는데, n의
크기를 갖는 샘플의 경우 df가 n-1인 t분포를 따른다. t분포는 N(0,1)과 유사한 형태이나 더 무거운 꼬리(heavier
tail)을 가진 형태를 보인다. df가 증가함에 따라 t분포는 표준정규분포(Z)에 가까워진다.
T = X bar-mu / (s/sqrt(n)) ~ t(n-1)

3) 우리가 뽑은 표본의 평균값이 모평균과 동일한지 확인하는 방법은 두 가지가 있다.
a. 모평균의 분포 범위를 구한 뒤, 샘플의 평균이 그 내부에 위치하는지를 확인한다.
분포 범위는 확률변수가 따르는 확률 분포에 따라 다르며, t분포의 예를 들면 다음과 같다.
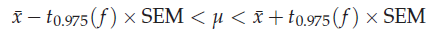
b. 확률분포에 따라 확률변수가 갖는 값에 대응되는 p-value, 즉 영가설이 참일 경우 관찰된 확률변수값이
나올 확률을 구한 뒤 이 확률이 significant한 레벨인지 확인을 하는 것이다.
4) 만약 영가설에 비해 데이터의 방향성이 한쪽으로 정해지는 경우는 단측검정(one-sided test)를 사용할 수도
있다. 이 경우, 동일한 유의성을 갖는 양측 검정에 비해 더 낮은 cutoff point를 갖게 된다. 따라서 검정이 더
용이한 부분도 있지만, 조심해서 사용해야 함. 특히 논문에서 one-sided를 사용하는 경우는 명확히 언급을 해야
하며 nonsignificant 한 data를 significant하게 만들기 위해 one-sided를 이용하는 경우는 부정한 것으로 간주됨.
5) 데이터 분석의 상황에 따라 전형적으로 사용하는 분석들이 있다. 아래는 연속형 자료의 분석에 관한 부분이다.
a. One sample test
- 하나의 sample이 우리가 알고 있는/예상하는 모평균값을 갖는지 여부를 확인함.
- 정규분포를 따르는 경우, t test / 따르지 않는 경우, Wilcoxon signed rank test를 시행함.
- Wilcoxon test: 각 값에서 가정된 평균 mu0값을 각 요소에서 뺀 뒤, 절대값에 따라 rank를 부여한다. 그 다음
(X-mu0) 값의 부호(양/음)에 따라 rank의 합을 구한다. 만약 데이터가 mu0를 중심으로 분포가 되어 있다면,
양/음의 분포는 거의 동일할 것이다. 이를 표준정규분포에 적용해 p 값을 얻을 수 있다.
b. Two sample test
- 정규분포를 따르는 경우, t test / 따르지 않는 경우, Mann-Whitney U test를 시행함.
(Mann-Whitney U test = two sample Wilcoxon singed-rank test)
- 두 집단의 분산이 동일하다는 가정(등분산 가정)이 들어간다. 분산의 동일성은 var.test()로 확인 가능.
c. Paired test
- 동일 환자의 치료 전-후 성적 비교와 같이 짝지어진 개체 별로 비교를 할 때 사용됨.
- 원리는, 두 짝지어진 개체값의 차를 구한 뒤 이를 one sample test(mu=0)로 간주하는 것이다: t-test, Wilcoxon
test 모두 사용 가능.
d. More than 3 samples
- 독립성/정규성/등분산성이 만족되는 경우, One-way ANOVA를 시행
- 각각의 가정을 만족시키지 못한 경우
독립성: 독립된 그룹 간 비교가 아닌 경우, 예를 들면 같은 개체를 대상으로 한 반복 측정: RM-ANOVA
정규분포가 아닌 경우: Kruskal-Wallis 시행,
등분산성이 가정되지 않는 경우: Welch의 강건한 분산분석 시행
- ANOVA 등을 시행해 "n개의 그룹이 모두 같진 않음"을 밝혔다면, 어떤 그룹 간 차이가 존재하는지는 사후분석
(post-hoc analysis)를 통해 조사해야 함.
* One-sample t test
기본 조건: 샘플은 정규분포를 갖는 모집단으로부터 추출되었다. X~ N(mu, sigma^2)
Null hypothesis: mu = mu0
t.test()

args
mu=n: 영가설에 사용하는 mu0값을 설정함. 기본값은 mu=0
alternative = "greater" or "less": one-side test로 변경하며, greater 혹은 less 어느 쪽인지 설정함.
conf.level = n: 신뢰수준을 변경 가능. 기본값은 0.95
* One-sample Wilcoxon signed-rank test
기본 조건: 정규성 가정이 필요하지 않음.
Null hypothesis: mu = mu0
wilcox.test()

args
mu: 가정된 평균 mu0를 의미함.
alternate: t test와 동일하게, "greater" or "less"로 설정해 one-side test 시행함.
correct="on" / "off" : 연속성 수정(continuity correction), 기본값은 "on"이다.
exact="on" / "off" : 정확성 검정(exact test)를 계산할 지 여부.
정확성 검정: 표본의 크기가 작아 검정 통계량의 근사분포의 정확성이 의심스러울 때 사용한다고 함.
Wilcoxon test의 문제점은 같은 순위의 값들을 어떻게 처리할 것인지 (ties)이다. 보통 동점인 값들의 rank의 평균값들을 전체적으로 부여하게 된다. 예를 들면 rank 6부터 9까지 동일한 경우, 4가지 데이터값에 모두 7.5등을 부여한다. 샘플의 크기가 큰 경우엔 괜찮지만 작은 sample에서는 정확한 p value 계산이 불가능하다.
* Two-sample t test
기본 조건: 샘플은 정규분포를 갖는 모집단으로부터 추출되었다. X~ N(mu, sigma^2)
기본 조건: 두 그룹이 독립이다. 즉, paired group엔 적용이 불가능함.
Null hypothesis: mu1 = mu2
확률변수 T
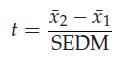
SEDM

SEDM은 등분산 가정을 만족하냐에 따라 두 가지로 계산될 수 있다.
a) 등분산 가정을 만족한다
- 각 group의 s값을 SEM1, SEM2를 계산하는데 사용할 수 있다.
- t값은 df = n1 + n2 -2의 t분포를 따르는 것으로 알려짐. T ~ t(n1+ n2-2)
b) 등분산 가정을 만족하지 못한다: 두 샘플이 추출된 모집단의 분산이 다르다
- Welch procedure: T는 t-분포를 따르지 않고, s1, s2, n1, n2로 계산된 df의 t 분포로 근사된다고 한다.
(df는 보통 정수가 아님)
(인용: With this procedure, t is actually not t-distributed, but its distribution may be approximated by a t distribution with a number of degrees of freedom that can be calculated from s1, s2, and the group sizes. This is generally not an integer.)
- 두 집단의 group size와 sd가 큰 차이가 나지 않는다면 a와 b 방법의 값은 비슷하다. 하지만 Welch가 더
안전한 방법으로 생각된다.
t.test()
t.test(데이터~factor)
boxplot이나 xtabs를 이용할 때와 같은 ~ operator를 사용할 수 있다. 의미도 동일: data를 factor에 따라 서술하라.
혹은, 일반적으로 두 집단의 데이터를 넣어서도 가능하다. t.test(data1, data2)

R에서 two-sample t-test는 기본적으로 Welch procedure를 이용한다. 따라서 일반적인 two-sample t-test를 하고 싶다면 var.equal=T 를 argument로 넣어줘야 한다.
Welch와 일반 t-test를 비교해보면, t값과 df, p value가 모두 조금 다른 것을 알 수 있다. 특히 Welch는 df가 정수가 아닌 유리수로 표시되었으나 일반 t-test는 정수이다. T값의 절대값은 two sample이 더 크고, p-value는 더 낮다. 즉, Welch가 더 엄밀한 테스트임을 짐작할 수 있다.
* Comparison of variances: 분산 비교
var.test()
F test를 이용해 두 그룹의 분산을 비교해준다. Two-sample t test처럼 동일하게 사용이 가능하다.
기본 조건: 두 그룹이 독립이다. 즉, paired group엔 적용이 불가능함.
Null hypothesis: 두 그룹의 분산이 같다

두 그룹의 분산이 같은 것이 영가설이므로, p-value > 0.05인 경우 영가설을 기각하지 못하고 등분산을 가정함.
* Two-sample Wilcoxon signed-rank test
기본 조건: 두 그룹이 독립이다. 즉, paired group엔 적용이 불가능함.
기본 조건: 정규성 가정이 필요하지 않음.
Null hypothesis: mu1 = mu2

모든 데이터를 풀어 오름차순으로 정렬한 후, rank를 부여한다. 이후 group별로 rank의 합을 구한다.
위 test의 W값은 다음과 같다: 첫번째 그룹의 자료의 rank에서 이론적 최소값을 뺀 값을 모두 합한 것으로, 첫번째 그룹이 더 큰 경우는 양의 값이 나오며 더 작은 경우는 0이 나온다. 따라서 모든 경우에 첫번째 그룹이 작다면 W=0이 될 것이다. 교과서 인용 참조 ("The test statisticW is the sum of ranks in the first group minus its theoretical
minimum (i.e., it is zero if all the smallest values fall in the first group). Some textbooks use a statistic that is the sum of ranks in the smallest group with no minimum correction, which is of course equivalent.")
* Paired sample t test
기본 조건: 독립성 조건을 만족하지 않는다. Paired test 이기 때문이다.
기본 조건: 샘플은 정규분포를 갖는 모집단으로부터 추출되었다. X~ N(mu, sigma^2)
같은 실험단위에서 측정한 두 결과를 비교할 때 paired t test를 사용할 수 있다. 기본적인 원리는 두 pair의 차를 구한 값을 하나의 새로운 변수로 두고, 이 변수를 one-sample t test를 시행하는 개념이다.
t.test(data1, data2, paired=T)

One-sample t-test와 원리적으로 동일해서 새로울 것은 없다. 다만 paired된 실험결과를 unpaired인 것 처럼 통계를 돌리는 경우, 굉장히 다른 결과가 나올 수 있으므로 이 점을 명심해야 한다.
* The matched-pairs Wilcoxon test
마찬가지로 one-sample Wilcoxon과 거의 동일하다.

'[학습] 데이터분석방법론: R' 카테고리의 다른 글
| Introductory statistics with R: chapter 7 (0) | 2021.03.24 |
|---|---|
| Introductory statistics with R: chapter 6 (0) | 2021.03.18 |
| Introductory statistics with R: chapter 4 (0) | 2021.03.17 |
| Introductory statistics with R: chapter 3 (0) | 2021.03.14 |
| Introductory statistics with R: chapter 2 (0) | 2021.03.11 |



