*참고자료: introductory statistics with R, 기타 블로그 및 R 개론서
* 한마디
Exercise 문제가 배운 내용에 비해 난이도가 있는 듯 하다. 열심히 풀어서 내 것으로 만들자.
* 범위: chapter 2
* 기본 명령어
summary(): 해당 데이터의 최대/최소/평균/중간값 등을 요약해서 보여줌.
runif(): 균일분포에 따른 난수를 생성해줌.
rnorm(): 정규분포에 따른 난수를 생성해줌.
paste(): 나열된 원소를 공백을 사이에 두고 이어붙여 결과값으로 제공함.
paste(개별 요소): 이어붙여 하나의 결과값을 제공함.
paste(벡터 등 묶인 요소): 각 원소로 분해해, 원소의 개수 만큼 결과값을 제공함.

paste(벡터1, 벡터2): 벡터 1과 벡터2의 각 대응 요소를 매칭해서 원소의 개수 만큼 결과값을 제공함.
원소의 개수가 다른 경우, 짧은 쪽을 반복해서 돌려줌.

paste0(): 나열된 원소를 공백 없이 이어붙여 결과값을 제공함.
range(): 입력된 수 중 가장 작은 수, 가장 큰 수를 리턴함 - 즉, 범위를 알려줌.
진리값에 대한 정보 얻기: sum, mean, all, any
sum(조건): 결과값 중 TRUE가 몇 개 인지
mean(조건): 결과값 중 TRUE의 비율을 보여줌
any(조건): 결과값 중 TRUE가 되는 것이 한개라도 있다면, TRUE를 반환.
all(조건): 결과값이 모두 TRUE이면 TRUE를 반환함.
* Scripting
R의 기본은 대화형 언어이나, 일정 정도 이상 데이터나 코드가 복잡해지는 경우 계속 대화형으로 진행하기 어려움이 있다. 이 때는 R studio에 제공되는 R script를 이용해서 코드를 작성 후 실행하면 된다.
* Package
CRAN으로부터 필요한 패키지를 다운받아 사용할 수 있으며, 패키지를 사용할 땐 libraray(패키지이름)을 사용하고, 사용을 중지하고 싶을 땐 detach("package:패키지이름") 명령어를 사용한다.
* Attach & detach
Data frame의 column을 $없이 바로 꺼내서 쓰기 위한 명령어.
Attach(데이터프레임)을 사용하면, 그 데이터 프레임 변수가 system의 search path에 들어가서 마치 패키지의 하나인 것 처럼 기능한다.
Attach(thuesen)을 이용한 다음 search()로 search path를 확인한 아래 데이터를 확인해보자.

thuesen이 .GlobalEnv(=workspace) 바로 뒷순서로, 대부분의 package보다 앞에 있다. 변수명이 중복되는 경우 앞쪽부터 찾아쓰는 규칙이 있으므로 attach()로 search path에 등록한 data frame은 상당히 높은 우선순위를 갖는다. 물론 work space, 즉 내가 프로그램 안에서 정의한 변수가 먼저 찾아지기 때문에 등록할 data frame 내부의 data 이름과 겹치는 것이 없는지 확인해야 한다.
또한, attach()는 원본 data frame의 copy를 등록하는 개념이므로 원본을 수정해도 attach()된 object에 영향은 없다.
여러 data frame을 등록할 수 있으며, 새로 들어온 data frame이 항상 2번째 자리로 가고 나머지는 하나씩 밀려남.
detach()를 사용해 search path의 data frame을 제거할 수 있으며, argument를 넣지 않는 경우는 자동으로 2번 자리에 있는 data frame이 제거된다. .GlobalEnv나 package들은 제거되지 않는다.
* Subset, transform and within
subset(): 특정 부분의 데이터를 추출하는데 사용함.

transform(): 변수값에 대한 연산결과를 데이터프레임의 다른 변수에 저장하는 함수.
연계된 계산(chained calculation)이 불가능해 한계가 있는 함수라고 함. within()을 더 많이 쓴다고 함.

* With(), within()
데이터 프레임 또는 리스트 내 필드를 손쉽게 접근하기 위한 함수. With은 데이터에 대한 접근만, within()은 데이터를 수정까지 할 수 있다는 점이 다름.

이 때, 중괄호 내에서는 attach()를 썼을 때와 마찬가지로 $ 없이 data frame 내의 변수를 편하게 조작할 수 있다. 심지어 중간 변수를 만들었다가 마지막에 rm()으로 제거할 수도 있음.

* The graphics subsystem: 데이터 시각화
plot()
가장 간단한 방법으로, 의외로 데이터를 별 생각 없이 넘겨주어도 자동으로 적절한 형태의 그래프를 찾아서 그려준다.
plot() 함수의 주요 arguments
xlab, ylab: x,y축 이름
main: 그래프 제목 (위에 표시)
sub: subtitle (아래에 표시)
pch: 점의 종류

cex: plot하는 점의 크기 (기본값: cex=1)
col: plot하는 점의 색상. "red", "blue" 이런 식으로도 사용이 가능하나, 자세한 색 지정은 아래 색상표 참조.

axis 관련
plot(…, axes=F) : 축을 그리지 않음
xlim, ylim: x, y축의 값 범위, 최소/최대값을 갖는 벡터를 지정해줄 수 있다. xlim=c(0,4) 와 같이 사용.
type: 그래프의 유형

lty: type='l'인 선 그래프에서 선의 유형 설정.

featurePlot(데이터, 분류기준, 그림유형)
carrot 패키지에 있는 함수로, "데이터"를 plot하는데 "분류기준"에 따라 다른 색으로 그려준다.
그림 유형은 "ellipse", "strip", "box", "pairs", "density" 등이 있음.
points()
이미 생성된 plot에 점을 추가로 그려줌.
points(x축, y축, 옵션들): 옵션들은 plot과 동일한 듯.
lines()
이미 생성된 plot에 선그래프를 추가해줌.
lines(x축, y축, lty=라인타입)
abline()
lines는 꺾은 선을 그려주는 반면, abline은 직선만 그릴 수 있음.
v=값, h=값 을 입력하는 경우 해당 값에 수직/수평선이 그려지며
a=y절편, b=기울기 를 입력하는 경우 y= a+bx 의 직선이 그려진다.
abline(v=3), abline(h=2)
abline(a=3, b=-1, col="red", lty=3)
등과 같이 사용이 가능함. 특히 lm, glm 등의 회귀모형에서 abline을 이용하면 바로 선을 그려줌.
curve()
주어진 표현식에 대한 곡선을 그리는 함수.
legend()
범례를 표시하는데 사용함.
legend(x좌표, y좌표, 표시할 범례)
좌표값 대신 "left", "topleft", "bottom", "center" 등으로 위치 지정 가능.
legend("위치", 들어갈 내용(벡터가능), pch=점모양, title="범례 제목")
"위치"에 locator(n=1)을 넣으면 처음 mouse click하는 쪽에 생김.

text()
그래프에 문자열을 표시하는데 사용함.
text(x좌표, y좌표, labels="표시할 문자", adj=정렬옵션)
adj (0,0)은 우측 상단, (0,1)은 우측 하단, (1,0)은 좌측 상단, (1,1)은 좌측 하단
mtext()
그래프의 외부 마진 영역(1하단, 2좌측, 3상단, 4우측)에 문자를 추가한다.
mtext("문자열", side=문자추가위치, line=문자와 그래프 마진과의 거리, adj=정렬, outer=내부/외부마진 여부)
문자추가위치: 1=bottom, 2=left, 3=top(=default), 4=right
문자와 그래프 마진과의 거리: 0이 기본, 클 수록 멀어짐
adj=0은 왼쪽/아래 정렬, 1은 위쪽/오른쪽 정렬, 생략은 중앙 정렬
outer=TRUE는 외부마진에 문자 추가, FALSE는 내부 마진에 문자 추가
이외에 폰트, 색깔, 크기 등 옵션 추가 가능. (font=2는 boldface)

axis(side, at=NULL, labels=TRUE, tick=TRUE, … 등등.)
plot margin(축)을 그리는 명령어.
side: 1은 x축 bottom, 2는 y축 left, 3은 x축 top, 4는 y축 right
at: 기준점 정의. (벡터값)
axis(2, at=seq(0.2,1.8,0.2)
tick: 눈금 표시 여부
box(): plot의 axis margin을 box로 그려줌.
boxplot()
박스플롯을 보여줌. 박스플롯의 상세 내용(최대, 최소, 1사/3사분위값, 중앙값, outlier)을 알려면 변수에 할당하여 반환값을 확인하면 된다.
변수 <- boxplot(데이터)
이 때 변수를 호출하면 출력되는 데이터 중 $stat이 갖고 있는 데이터가 순서에 따라 다음 의미를 나타낸다: lower whisker, lower hinge, 중앙값, upper hinge, upperwhisker 이외에도 다양한 값을 알려줌.
barplot()
막대그림 그려줌
hist()
히스토그램을 그려줌.
freq=T/F : freq=T 인 경우 실제 count를, freq=F인 경우 비율(density)를 표시함.
polygon()
다각형을 그릴 수 있음.
arrows(x1,y1,x2,y2, 옵션)
화살표를 그릴 수 있음. 옵션: length=길이, angle=화살표 각, code=화살표 종류

* Building a plot from pieces: 부분 부분 plot 완성하기
복잡한 데이터의 경우, separate drawing command가 유용할 수 있음.

위와 같은 명령어를 사용하는 경우, 실질적으로 plot과 axis 모두 그려지지 않아서 결과값은 흰 배경으로 표시된다. 하지만 내부적으로는 시각적으로 표시되지만 않았을 뿐이지, plot은 모두 진행된 상태.

plot 이후 separate drawing을 해주는 명령어들을 이용해 그림을 차례차례 완성시켜나갈 수 있다.
특히, 각 그룹 별로 다른 색으로 plot을 하기 윈하는 경우, 모든 데이터를 type="n"을 이용해 보이지 않게 plot을 해서 전체를 표시할 수 있는 적절한 dimension을 확보한 후 points() 명령어를 통해 각 group 별로 plot을 할 수 있다.
* par() 함수 사용하기
굉장히 세밀하게 plot을 조절해 그릴 수 있지만, beginner한테는 어려울 수 있음. 특히 parameter가 굉장히 많아서 필요할 때 ?par 명령어로 help page를 호출해 참고하여 사용하도록 한다.
* Plot들 조합하기
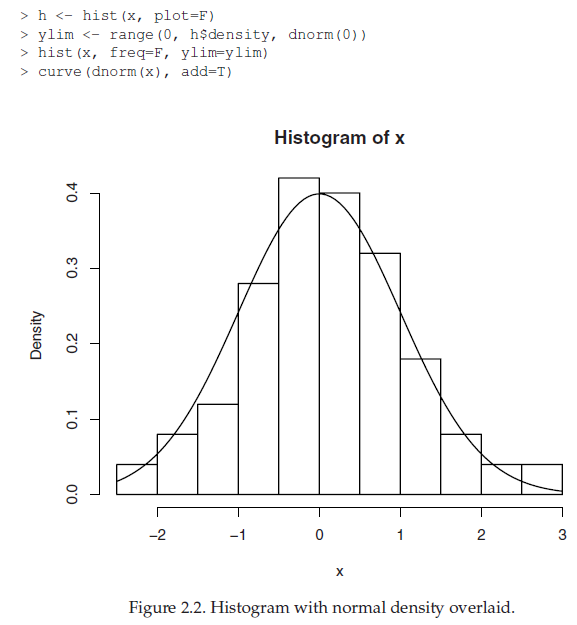
하나의 plot에 여러 요소를 조합하는 것이 필요한 경우도 있다 (예를 들어, 확률밀도함수 그림에 histogram을 덧그림).

위의 코드를 분석해보면, x는 정규분포를 따르는 100개의 난수를 포함한다. histogram으로 x를 plot하는데, freq=F 를 이용해 실제 갯수가 아닌 frequency(=density, 0-1 사이의 값)으로 나타내도록 했다. dnorm은 입력된 벡터에 대해 확률 밀도함수값을 계산해주는 함수로, dnorm(x) 명령을 이용해 100개의 난수 벡터 x에 대해 각각의 확률 밀도값을 계산한 다음 curve 함수를 이용해 이를 곡선으로 plot해주는 것이다. add=T/F: T의 경우 기존에 존재하는 plot 위에 겹쳐 그림을 의미.
하지만 가끔 밀도그래프의 끝부분이 잘릴 수 있는데, 왜냐하면 histogram은 x 벡터로 그려진 것이지, dnorm 값을 이용한 것이 아니기 때문에 때문.
해결책은, 아래처럼 ylim 값을 range(0, h$density, dnorm(0))을 이용해 가장 큰 범위값으로 설정하면 된다. h<- hist(x,plot=F) 명령어를 사용하면 실제 plot이 되진 않지만 h에 histogram plot에 필요한 여러 값들이 들어가게 된다.
h$density는 histogram의 모든 density 값을 의미하며, dnorm(0)을 사용한 이유는 dnorm이 0에서 가장 큰 값을 갖기 때문이다. range()는 입력된 값 중 가장 작은 값, 가장 큰 값/ 즉 분포의 범위를 알려주는 함수.
* R programming: 함수 만들기
이 책에서는 기본 통계 과정들을 다루느라 함수에 대해 많이 다루진 않겠지만, 아래와 같이 함수를 정의해 편하게 사용할 수 있음. 아래 코드는 바로 위에 있는 histogram과 정규분포를 한번에 그려주는 함수임.

Substitute() & deparse()
substitute가 반환하는 것을 표현식이다. substitute는 프로미스라는 특별한 유형의 개체를 반환하는데, 프로미스는 값이 계산되기 위해 필요한 표현과 계산하기 위한 환경을 파악한 것이다.
deparse()는 객체를 문자로 전환해준다. 따라서 deparse(substitute(x)) 조합이 많이 쓰이는데, x의 표현식을 가져와서 문자열로 바꿔버리는 것이다. 위의 코드에서 생각해보면 hist.with.normal()에 넣는 argument를 x로 받기 때문에, 예를 들어 hist.with.normal(rnorm(100))과 같이 입력한다면 이 표현식을 가져와 이를 문자열로 변경하여 x축의 이름 (즉, "rnorm(100)") 으로 사용한다. 단, x<-rnorm(100), hist.with.normal(x) 처럼 사용하는 경우는 x가 표현식이 아닌 난수 벡터로 확정되었으므로 xlab은 그냥 "x"가 된다.
* Flow control: 조건 반복문
R의 프로그래밍 언어로서의 면모를 볼 수 있는 부분. while과 repeat 문을 살펴보자.
while(조건) 표현식 : 조건이 참인 경우 계속 표현식을 시행함.
repeat{ 표현식 }: 무조건 표현식을 반복하게 되므로 내부에 if, break 문을 넣어줘야 함.
for문 역시 다른 프로그래밍 언어와 동일하게 이용할 수 있음.
* Data entry: 데이터 입력하기
어떻게 외부 data file을 불러오고 사용하고, 편집하는지를 알아봄.
read.table()
data frame으로 불러옴.
header=T/F : column 이름을 포함하는 header가 있는지를 나타내는 argument.
na.string="" : 결측치를 어떻게 표시할 지.
fill or flush: 각 column 들의 길이가 다른 경우, 보통은 error로 간주되지만 fill이나 flush argument를 써서 채운 뒤 로딩.
read.table("clipboard"): 클립보드에 있는 자료를 가져옴.
read.csv(), read.csv2()
CSV파일을 불러오기 위한 명령어. read.csv()는 ,로 구분된 문서를, read.csv2()는 ;로 구분된 문서를 불러온다.
두 함수 모두 header=T 가 default로 설정되어 있음.
read.delim(), read.delim2()
delimited file을 불러오기 위해.
read.xlsx
xlsx 패키지를 설치해야 한다: install.packages("xlsx"), library(xlsx)
read.xlsx("불러오려는 엑셀파일명", 엑셀파일안에서 불러오려는 시트 번호)
이외에도 여러 다른 package 들이 있다.
"foreign" 패키지
SPSS(.sav format), SAS(export libraries), Epi-info(.rec), Stata, Systat, Minitab, S-PLUS version 3 dump file 등 다양한 외부 프로그램의 데이터를 불러올 수 있는 패키지.
* Data editor
변수 <- edit(데이터프레임) 명령어를 사용하는 경우, 아래와 같은 자체 편집기가 나타난다. 편집을 완료한 후 편집기를 닫으면 변경된 데이터가 변수에 저장된다. 입력된 원본 데이터프레임은 intact 하다.

오리지널 데이터를 변경하고 싶다면, fix(데이터프레임) 명령어를 사용할 수 있다.
dd<- data.frame()
fix(dd)
와 같이 빈 data frame을 만들어서 editor를 활성화시켜 자료를 만들 수 있다.
'[학습] 데이터분석방법론: R' 카테고리의 다른 글
| Introductory statistics with R: chapter 6 (0) | 2021.03.18 |
|---|---|
| Introductory statistics with R: chapter 5 (0) | 2021.03.17 |
| Introductory statistics with R: chapter 4 (0) | 2021.03.17 |
| Introductory statistics with R: chapter 3 (0) | 2021.03.14 |
| Introductory statistics with R: chapter 1 (0) | 2021.03.07 |



